Tutorials
Einleitung Erste Schritte Sprachsynthese Spracherkennung Grammatiken
Sprachsynthese
DialogOS enthält ein eingebautes Text-to-Speech-System, welches es erlaubt beliebige Texte vorzulesen. Der zu sprechende Text muss also – in der Theorie – nur eingetippt werden. Keine Sprachsynthese funktioniert jedoch jemals perfekt, jedenfalls nicht immer im ersten Anlauf. In diesem Tutorial soll darauf eingegangen werden, wie die Sprachsynthese beeinflusst werden kann.
Mit einem Doppelklick auf den zu ändernden Sprachausgabe-Knoten können die Eigenschaften desselben bearbeitet werden. Um die Eigenschaften der Sprachsynthese zu konfigurieren, wählt den Reiter Sprachausgabe.
Unterschiedliche Stimmen
An jedem Sprachausgabe-Knoten kann, im Drop-Down Menü Stimme, gesondert ausgewählt werden mit welcher Stimme der angegebene Text gesprochen werden soll.
Um die Stimme nicht für jeden Sprachausgabe-Knoten einzeln einstellen zu müssen, kann eine Standardstimme für den gesamten Dialog gesetzt werden. Hierzu müsst ihr im Menü Dialog (oberhalb der Symbolleiste) Sprachausgabe auswählen. Dann öffnet sich ein Fenster, in welchem u.a. die Standardstimme festgelegt werden kann.
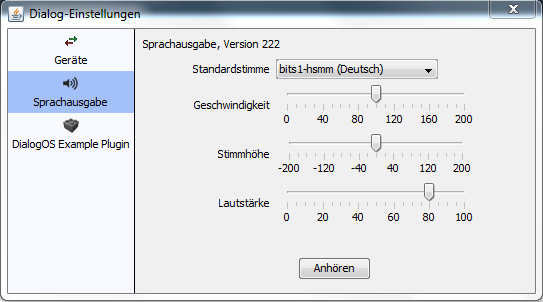
Alle nachfolgend erstellten Sprachausgabe-Knoten haben nun als Stimme die Standardstimme. Diese Einstellung kann natürlich an ausgewählten Knoten verändert werden.
(korrekte) Aussprache / Sprache
Bei der Auswahl einer Stimme muss beachtet werden, dass für die korrekte Aussprache eines deutschen Wortes oder Satzes auch eine deutsche Stimme gewählt werden muss. Für englische Wörter und Sätze entsprechend eine englische Stimme. Um vor Ausführung des Dialoges die Aussprache eines Wortes oder Satzes probeweise anzuhören, genügt ein einfacher Klick auf die Schaltfläche Anhören.
Beispiel: Um den Satz “Ich hör am liebsten Take That und Spice Girls!” richtig aussprechen zu lassen, kann man vier Sprachausgabe-Knoten nutzen, welche jeweils einen Teil des Satzes, in der entsprechenden Sprache, ausgeben.
Konkret: In den ersten Sprachausgabe-Knoten gebt ihr unter Ausgabe “Ich hör am liebsten” ein und wählt eine deutsche Stimme aus. Diese verbindet ihr mit dem zweiten Sprachausgabe-Knoten in welchen ihr “Take That” eingebt und diesmal eine englische Stimme einstellt. Analog fahrt ihr mit dem Verfahren fort. Für “und” wählt ihr wieder die deutsche Stimme, für “Spice Girls” eine englische. Sind die vier Knoten nacheinander miteinander verbunden und der Letzte mit einem Ende-Symbol, sollte der Satz korrekt ausgesprochen werden.
Abkürzungen / Zahlen
Namen, Zahlwörter (1998, 1. , 2. …), Abkürzungen u.a. werden evtl. von unterschiedlichen Stimmen unterschiedlich ausgesprochen. Hier heißt die Devise: Immer vorher ausprobieren!
Laufzeitverhalten
Standartmäßig wartet DialogOS, bis die aktuelle Sprachausgabe abgeschlossen ist, bevor der Dialog im nächsten Knoten fortgesetzt wird. Wird diese Option deaktiviert (Warten bis die Ausgabe abgeschlossen ist), wird der Dialog fortgesetzt, während das System noch spricht. So kann z.B. die Spracherkennung aktiviert werden o.a., während gleichzeitig noch die Sprachausgabe läuft.
Weiteres
Unter Ausgabe-Typ kann zwischen der Ausgabe als einfacher Text, als Ausdruck (hierbei wird der Text als Formel interpretiert) als MaryXML oder Groovy Skript gewählt werden. Mehr dazu im übernächsten Tutorial Grammatiken und der User-Documentation.
MaryXML
Als weiterer Reiter in den Sprachausgabe-Einstellungen ist MaryXML aufgeführt. Hier kann mit einem Klick auf Prompt to MaryXML eine einfache Eingabe in ein grundlegendes MaryXML-Dokument mit einigen Einstellungen umgewandelt werden, das dann weiter benutzt werden kann. In dem neu erstellten MaryXML-Dokument ist es nun möglich, viel präziser bspw. bestimmte Tonhöhen einzelner Textteile anzupassen. Näheres zu dem Editieren der einzelnen Einstellungen in der MaryXML-Dokumentation.